配置 ZRAM,实现 Linux 下的内存压缩,零成本低开销获得成倍内存扩增
本文完整阅读约需 88 分钟,如时间较长请考虑收藏后慢慢阅读~
由于项目需求,笔者最近在一台 Linux 服务器上部署了 ElasticSearch 集群,却发现运行过程中经常出现查询速度突然降低的问题,登录服务器后发现是物理内存不足,导致机器频繁发生页面交换。由于只是临时内存需求,没有提升配置的必要,而 ElasticSearch 中存储的数据主要是文本数据,因此笔者想到了使用 ZRAM 对内存进行压缩,以避免磁盘 IO 导致性能波动,效果明显。介于互联网上关于 Linux 配置 ZRAM 的文章少之又少,本文将为读者介绍在 Linux 中配置与使用 ZRAM 的过程,并借此机会介绍 ZRAM 以及 Linux 内存部分的运作机制。
目录
0x01 ZRAM 介绍
随着现代应用程序的多样化和复杂化发展,那个曾经只需要 640KB 内存就能运行市面上所有软件的时代已经一去不复返,而比应用程序发展更快的则是用户对多任务的需求。现在的主流操作系统都提供了内存压缩的功能,以保证活跃应用程序拥有尽可能多的可用内存:
macOS 从OS X 10.9之后默认开启内存压缩
Windows 从 Win10 TH2 之后默认开启内存压缩
大部分 Android 手机厂商都默认开启了内存压缩
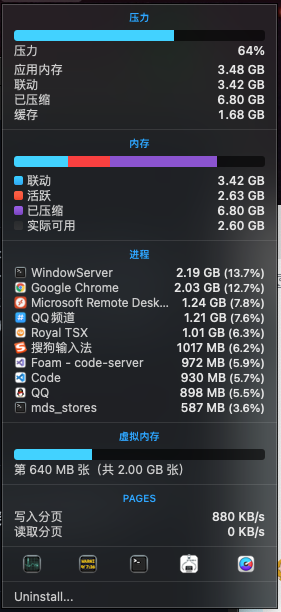

细心的读者会发现,在 Android 内存压缩的图中,并没有明确标明内存压缩,这是因为 Android(Linux)的内存压缩是依靠 Swap 机制实现的,大部分情况下是使用 ZRAM 技术来模拟 Swap。
ZRAM 早在 2014 年就伴随 Linux 3.14 内核合入主线,但由于 Linux 用途十分广泛,这一技术并非默认启用,只有 Android 和少部分的 Linux 桌面发行版如 Fedora 默认启用了这一技术,以保证多任务场景下内存的合理分层存储。
0x02 ZRAM 运行机制
ZRAM 的原理是划分一块内存区域作为虚拟的块设备(可以理解为支持透明压缩的内存文件系统),当系统内存不足出现页面交换时,可以将原本应该交换出去的页压缩后放在内存中,由于部分被『交换出去』的页得到了压缩,因此可用的物理内存就能随之变多。
由于 ZRAM 并没有改变 Linux 内存模型的基本结构,因此我们只能利用 Linux 中 Swap 的优先级能力,将 ZRAM 作为高优先级 Swap 看待,这也解释了为什么闪存比较脆弱的手机上会出现 Swap,其本质还是 ZRAM。
随着部分手机开始使用真正的固态硬盘,也有将 Swap 放在硬盘上的手机,但是一般也都会优先使用 ZRAM。
由于这一运行机制的存在,ZRAM 可以设计得足够简单:内存交换策略交给内核、压缩算法交给压缩库,ZRAM 本身基本上只需要实现块设备驱动,因此具有极强的可定制性和灵活性,这也是 Windows、macOS 等系统所无法比拟的。
Linux5.16 中关于 ZRAM 的源码只有不到 100KB,实现非常精简,对 Linux 驱动开发感兴趣的朋友也可以从这里开始研究:linux/Kconfig at v5.16 · torvalds/linux
0x03 ZRAM 配置与自启动
互联网上关于 ZRAM 的资料少之又少,因此笔者计划从 Linux 主线中 ZRAM 相关源码和官方文档着手分析。
1. 确认内核是否支持&有无启用 ZRAM
既然 ZRAM 是内核模块,就需要先检查当前 Linux 机器的内核是否存在这一模块。
在配置之前,需要读者先确认一下自己的内核版本是否在 3.14 以上,部分 VPS 由于依旧使用 Xen、OpenVZ 等虚拟/容器化技术,内核版本往往卡在 2.6,那么这样的机器是无法开启 ZRAM 的。笔者用作示例的机器安装的 Linux 内核版本为5.10,因此可以启用 ZRAM:

但根据内核版本判断毕竟不可靠,如 CentOS 7,虽然内核版本是 3.10,却支持 ZRAM,也有极少数发行版或嵌入式 Linux 为了降低资源占用,选择不编译 ZRAM,因此我们最好使用 modinfo 命令来检查一下有无 ZRAM 支持:
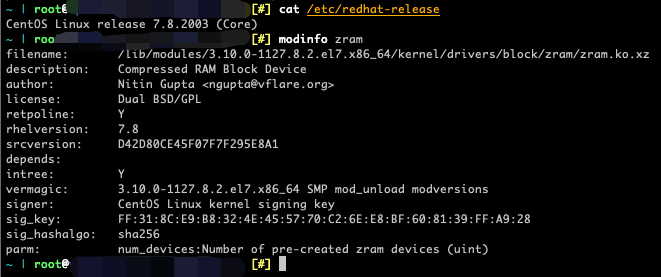
如图所示,虽然这台服务器是 CentOS 7.8,内核版本只到 3.10,却支持 ZRAM,因此使用 modinfo 命令是比较有效的。
部分发行版会默认启用但不配置 ZRAM,我们可以使用lsmod检查 ZRAM 是否启用:
lsmod | grep zram
2. 启用 ZRAM 内核模块
如果确定 ZRAM 没有被启用,我们可以新建文件 /etc/modules-load.d/zram.conf,并在其中输入 zram。重启机器,再执行一次 lsmod | grep zram ,当看到如下图所示的输出时,说明 ZRAM 已经启用,并能支持开机自启:

上文我们提到,ZRAM 本质上是块设备驱动,那么当我们输入 lsblk 会发生什么呢?
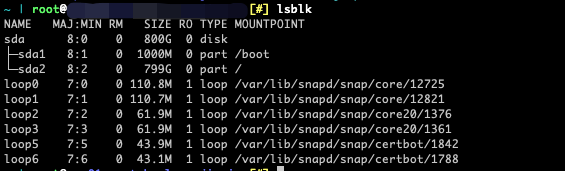
可以看到,其中并没有 zram 相关字眼,这是因为我们需要先新建一个块设备。
打开 ZRAM 源码 中的Kconfig文件,可以找到如下说明:
Creates virtual block devices called /dev/zramX (X = 0, 1, …).
Pages written to these disks are compressed and stored in memory
itself. These disks allow very fast I/O and compression provides
good amounts of memory savings.It has several use cases, for example: /tmp storage, use as swap
disks and maybe many more.See Documentation/admin-guide/blockdev/zram.rst for more information.
其中提到了一篇位于 Documentation/admin-guide/blockdev/zram.rst 的 说明文档。
根据说明文档,我们可以使用 modprobe zram num_devices=1 的方式来让内核在启用 ZRAM 模块时开启一个 ZRAM 设备(一般只需要一个就够了),但这样开启设备的方式依旧在重启后就会失效,并不方便。
好在modprobe的 说明文档 中提到了modprobe.d的存在:modprobe.d(5) – Linux manual page。
继续阅读 modprobe.d 的文档,我们会发现它主要用于modprobe时预定义参数,即只需要输入 modprobe zram,辅以 modprobe.d中的配置,就可以自动加上参数。由于我们使用 modules-load.d 实现了 ZRAM 模块的开机自启,因此只需要在modprobe.d中配置参数即可。
按照上文所述的文档,新建文件/etc/modprobe.d/zram.conf,在其中输入options zram num_devices=1,即可配置一个 ZRAM 块设备,同样重启后生效。
3. 配置 zram0 设备
重启后输入lsblk,却发现所需的 ZRAM 设备依旧没有出现?
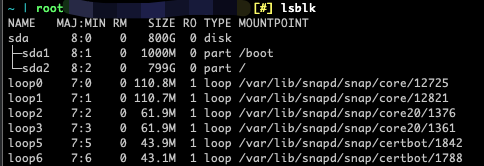
不用担心,这是因为我们还没有为这个块设备建立文件系统,lsblk虽然名字听起来像是列出块设备,但本质上读取的确是/sys目录里的文件系统信息,再将其与udev中的设备信息比对。
阅读udev的文档:udev(7) – Linux manual page,其中提到udev会从/etc/udev/rules.d目录读取设备信息,按照文档中的指示,我们新建一个名为/etc/udev/rules.d/99-zram.rules的文件,在其中写入如下内容:
KERNEL=="zram0",ATTR{disksize}="30G",TAG+="systemd"
其中,KERNEL属性用于指明具体设备,ATTR属性用于给设备传递参数,这里我们需要阅读zram的文档,其中提到:
Set disk size by writing the value to sysfs node ‘disksize’. The value can be either in bytes or you can use mem suffixes. Examples:
# Initialize /dev/zram0 with 50MB disksize echo $((50*1024*1024)) > /sys/block/zram0/disksize # Using mem suffixes echo 256K > /sys/block/zram0/disksize echo 512M > /sys/block/zram0/disksize echo 1G > /sys/block/zram0/disksizeNote: There is little point creating a zram of greater than twice the size of memory since we expect a 2:1 compression ratio. Note that zram uses about 0.1% of the size of the disk when not in use so a huge zram is wasteful.
即该块设备接受名为disksize的参数,且不建议分配内存容量两倍以上的 ZRAM 空间。笔者的 Linux 环境拥有 60G 内存,考虑到实际使用情况,设置了 30G 的 ZRAM,这样一来理想情况下就能获得60G - (30G / 2) + 30G > 75G以上的内存空间,已经足够使用(为什么要这样计算?请阅读『ZRAM 监控』一章)。读者可以根据自己的实际情况选择 ZRAM 空间大小,一般来说一开始可以设置小一些,不够用再扩大。
TAG属性用于标记设备类型(设备由谁管理),根据systemd.device的文档:systemd.device(5) – Linux manual page,大部分块设备和网络设备都建议标记 TAG 为systemd,这样systemd就可以将这个设备视作一个Unit,便于控制服务的依赖关系(如块设备加载成功后再启动服务等),这里我们也将其标记为systemd即可。
可以使用如dev-zram0.device或者dev-sda1.device等方式获取设备的 Device Unit

配置结束后,再次重启 Linux,就能在lsblk 命令中看到zram0设备了:
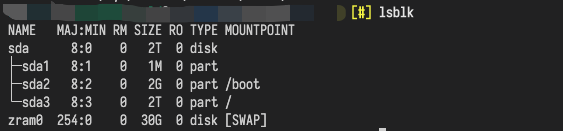
4. 将 zram0 设备配置为 Swap
获取到了一个 30G 大小的 ZRAM 设备,接下来需要做的就是将这个设备配置为 Swap,有经验的读者应该已经猜到接下来的操作了:
mkswap /dev/zram0
swapon /dev/zram0
是的,将zram0设备配置为 Swap 和将一个普通设备/分区/文件配置为 Swap 的方式是一模一样,但该如何让这一操作开机自动执行呢?
首先想到的自然是使用fstab,但好巧不巧,启用 ZRAM 内核模块使用的modules-load.d也难逃 Systemd 的魔爪:modules-load.d(5) – Linux manual page。既然从一开始就上了 Systemd 的贼船,那就贯彻到底吧!
在 Systemd 的体系下,开机自启的命令可以被注册为一个 Service Unit,我们新建一个文件/etc/systemd/system/zram.service,在其中写入如下内容:
[Unit]
Description=ZRAM
BindsTo=dev-zram0.device
After=dev-zram0.device
[Service]
Type=oneshot
RemainAfterExit=true
ExecStartPre=/sbin/mkswap /dev/zram0
ExecStart=/sbin/swapon -p 2 /dev/zram0
ExecStop=/sbin/swapoff /dev/zram0
[Install]
WantedBy=multi-user.target
接下来运行systemctl daemon-reload重载配置文件,再运行systemctl enable zram --now,如果没有出现报错,可以运行swapon -s 查看 Swap 状态,如果看到存在名为/dev/zram0的设备,恭喜你!现在 ZRAM 就已经配置完成并能实现自启动了~

这里为了帮助读者了解 ZRAM 和 Systemd 的原理,因此采取了全手动的配置方式。如果读者觉得比较麻烦,或有大规模部署的需求,可以使用 systemd/zram-generator: Systemd unit generator for zram devices,大部分默认启用 ZRAM 的发行版(如 Fedora)都使用了这一工具,编写配置文件后运行
systemctl enable /dev/zram0 --now即可启用 ZRAM。
5. 配置双层 Swap(可选)
上一节我们配置了 ZRAM,并将其设置为了 Swap,但此时 ZRAM 依旧是不生效的。为什么呢?眼尖的读者应该发现了,/.swapfile的优先级高于/dev/zram0,这导致当 Linux 需要交换内存时,依旧会优先将页换入/.swapfile,而非 ZRAM。
解决这个问题可以通过两种方式:禁用 Swapfile,或者降低 Swapfile 的优先级,这里为了避免 ZRAM 耗尽后出现 OOM 导致服务掉线,我们采取后者,即配置双层 Swap,当高优先级的 ZRAM 耗尽后,会继续使用低优先级的 Swapfile。
我们打开 Swapfile 的配置文件(笔者的配置文件在/etc/fstab中),增加如下图所示参数:

如果使用其他方式配置 Swapfile(如 Systemd),只要保证执行swapon时携带-p参数即可,数字越低,优先级越低。对于 ZRAM 同理,如上文的zram.service中就配置 ZRAM 的优先级为 2。
设置后重启 Linux,再次执行 swapon -s 查看 Swap 状态,保证 ZRAM 优先级高于其他 Swap 优先级即可:

0x04 ZRAM 监控
启用 ZRAM 后,我们该如何查看 ZRAM 的实际效用,如压缩前后大小,以及压缩率等状态呢?
最直接的办法自然是查看驱动的 源码,和 文档,可以发现函数mm_stat_show()定义了/sys/block/zram0/mm_stat文件的输出结果,从左到右分别代表:
$ cat /sys/block/zram0/mm_stat
orig_data_size - 当前压缩前大小 (Byte)
4096
compr_data_size - 当前压缩后大小 (Byte)
74
mem_used_total - 当前总内存消耗,包含元数据等 Overhead(Byte)
12288
mem_limit - 当前最大内存消耗限制(页)
0
mem_used_max - 历史最高内存用量(页)
1223118848
same_pages - 当前相同(可被压缩)的页
0
pages_compacted - 历史从 RAM 压缩到 ZRAM 的页
50863
huge_pages - 当前无法被压缩的页(巨页)
0
该文件适合输出到各种监控软件进行监控,但无论是 Byte 还是页,这些裸数值依旧不便阅读,好在util-linux包提供了一个名为zramctl的工具(和 systemctl 其实是雷锋与雷峰塔的关系),在安装util-linux后执行zramctl,即可获得下图所示的结果:

根据上文mm_stat的输出,可以类推每项数值的含义,或者我们可以找到zramctl的 源码,了解每项输出的含义与单位:
static const struct colinfo infos[] = {
[COL_NAME] = { "NAME", 0.25, 0, N_("zram device name") },
[COL_DISKSIZE] = { "DISKSIZE", 5, SCOLS_FL_RIGHT, N_("limit on the uncompressed amount of data") },
[COL_ORIG_SIZE] = { "DATA", 5, SCOLS_FL_RIGHT, N_("uncompressed size of stored data") },
[COL_COMP_SIZE] = { "COMPR", 5, SCOLS_FL_RIGHT, N_("compressed size of stored data") },
[COL_ALGORITHM] = { "ALGORITHM", 3, 0, N_("the selected compression algorithm") },
[COL_STREAMS] = { "STREAMS", 3, SCOLS_FL_RIGHT, N_("number of concurrent compress operations") },
[COL_ZEROPAGES] = { "ZERO-PAGES", 3, SCOLS_FL_RIGHT, N_("empty pages with no allocated memory") },
[COL_MEMTOTAL] = { "TOTAL", 5, SCOLS_FL_RIGHT, N_("all memory including allocator fragmentation and metadata overhead") },
[COL_MEMLIMIT] = { "MEM-LIMIT", 5, SCOLS_FL_RIGHT, N_("memory limit used to store compressed data") },
[COL_MEMUSED] = { "MEM-USED", 5, SCOLS_FL_RIGHT, N_("memory zram have been consumed to store compressed data") },
[COL_MIGRATED] = { "MIGRATED", 5, SCOLS_FL_RIGHT, N_("number of objects migrated by compaction") },
[COL_MOUNTPOINT]= { "MOUNTPOINT",0.10, SCOLS_FL_TRUNC, N_("where the device is mounted") },
};
部分未默认输出的数值可以通过zramctl --output-all输出:

这个工具的输出结果混淆了 Byte 和页,混淆了历史最高、累计和当前的数值,且将不设置的参数(如内存限制)显示为 0B,因此输出结果仅作为参考,可读性依旧不高,一般来说只用了解DATA和COMPR字段即可。
结合zramctl和mm_stat的输出,不难发现我们配置的 ZRAM 大小其实是未压缩的大小,而非是压缩后的大小,前面我们提到了一个算法,当 ZRAM 大小为 30GB 且压缩率为 2:1 时,可以获得60G - (30G / 2) + 30G > 75G的可用内存,这就是假设了 30GB 的未压缩数据可以压缩到 15G,占用 15G 物理内存空间,即60G - (30G / 2),然后再加上 ZRAM 能存储最大的内存数据 30G 计算出来。
计算压缩率的方式为 DATA / COMPR,以引言中提到 ElasticSearch 的工作负载为例,如下图所示,默认压缩率为1.1G / 97M = 11.6。考虑到 ElasticSearch 的数据主要是纯文本,而 JVM 的机制也是提前向系统申请内存,能达到这样的压缩率已经非常令人满意了。

0x05 ZRAM 调优
尽管 ZRAM 的设置非常简单,其依然提供了大量可配置项供用户调整,如果在默认配置 ZRAM 后依旧觉得不满意,或者想要进一步发掘 ZRAM 的潜力,就需要对其进行优化。
1. 选择最适合的压缩算法
如上图所示,ZRAM 目前的默认压缩算法一般是lzo-rle,但其实 ZRAM 支持的压缩算法有很多,我们可以通过 cat /sys/block/zram0/comp_algorithm 获取支持的算法,当前启用的算法被[]括起来:

压缩是一个时间换空间的操作,也就意味着这些压缩算法并不存在绝对优劣,只存在不同情况下的取舍,有的压缩率高、有的带宽大、有的 CPU 消耗少……在不同的硬件上,不同的选择也会遇到不同的瓶颈,因此只有进行真实的测试,才能帮助选择最适合的压缩算法。
为了不影响生产环境,且避免 Dump 内存引起数据泄露,笔者使用另一台相同硬件的虚拟机进行测试,该虚拟机有 2G 的 RAM 和 2G 的 ZRAM,同样运行着 ElasticSearch(但数据量较小),然后使用stress工具对内存施加 1GB 的压力,此时不活跃的内存(即 ElasticSearch 中的部分数据)则会被换出到 ZRAM 中,如图所示:

使用如下脚本获得其中 512M 内存,将其 Dump 到文件中:
pv -s 512M -S /dev/zram0 > "./test-memory.bin"

接下来,笔者释放掉负载,空出足够的物理内存,在 root 用户下使用修改自 better_benchmarks.bash – Pastebin.com 的脚本对不同算法和不同page_cluster(下一节会提到)进行测试:LuRenJiasWorld/zram-config-benchmark.sh。
测试过程中我们会看到新的 ZRAM 设备被建立,这是因为脚本会将之前 Dump 的内存写入到这些设备,每一个设备都配置了不同的压缩算法:

在使用此脚本之前,建议先阅读一遍脚本内容,根据自己的需要选择不同的内存大小、ZRAM 设备大小、测试算法和参数等配置。根据配置不同,测试可能会持续 20~40 分钟,这个过程中不建议进行任何其他操作,避免干扰测试结果。
测试结束后,使用普通用户运行脚本,获取 CSV 格式的测试结果,将其保存成文件,导入到 Excel 中即可查看结果。以下是笔者环境下的测试数据:
algo | page-cluster| "MiB/s" | "IOPS" | "Mean Latency (ns)"| "99% Latency (ns)"
-------|-------------|-------------------|---------------|--------------------|-------------------
lzo | 1 | 9130.553415506836 | 1168710.932773| 5951.70401 | 27264
lzo | 2 | 11533.120699842773| 738119.747899 | 9902.73897 | 41728
lzo | 3 | 13018.8484358584 | 416603.10084 | 18137.20228 | 69120
lzo | 0 | 6360.546916032226 | 1628299.941176| 3998.240967 | 18048
zstd | 1 | 4964.754078584961 | 635488.478992 | 11483.876873 | 53504
zstd | 2 | 5908.13019465625 | 378120.226891 | 19977.785468 | 85504
zstd | 3 | 6350.650210083984 | 203220.823529 | 37959.488813 | 150528
zstd | 0 | 3859.24347590625 | 987966.134454 | 7030.453683 | 35072
lz4 | 1 | 11200.088793330078| 1433611.218487| 4662.844947 | 22144
lz4 | 2 | 15353.485367975585| 982623 | 7192.215964 | 30080
lz4 | 3 | 18335.66823135547 | 586741.184874 | 12609.004058 | 45824
lz4 | 0 | 7744.197593880859 | 1982514.554622| 3203.723399 | 9920
lz4hc | 1 | 12071.730649291016| 1545181.588235| 4335.736901 | 20352
lz4hc | 2 | 15731.791228991211| 1006834.563025| 6973.420236 | 29312
lz4hc | 3 | 19495.514164259766| 623856.420168 | 11793.367214 | 43264
lz4hc | 0 | 7583.852120536133 | 1941466.478992| 3189.297915 | 9408
lzo-rle| 1 | 9641.897805606446 | 1234162.857143| 5559.790869 | 25728
lzo-rle| 2 | 11669.048803505859| 746819.092437 | 9682.723915 | 41728
lzo-rle| 3 | 13896.739553243164| 444695.663866 | 16870.123274 | 64768
lzo-rle| 0 | 6799.982996323242 | 1740795.689076| 3711.587765 | 15680
842 | 1 | 2742.551544446289 | 351046.621849 | 21805.615246 | 107008
842 | 2 | 2930.5026999082033| 187552.218487 | 41516.15757 | 193536
842 | 3 | 2974.563821231445 | 95185.840336 | 82637.91368 | 366592
842 | 0 | 2404.3125984765625| 615504.008403 | 12026.749364 | 63232
从上表我们可以获取到非常多信息,表头从左到右分别为:
- 压缩算法
page-cluster参数(下一节解释其含义)- 吞吐带宽(越大越好)
- IOPS(越大越好)
- 平均延迟(越小越好)
- 99 分位延迟(越小越好)(用于获取延迟最大值)。
由于不同page-cluster情况下的压缩率是一样大的,该表格未能反映此情况,我们需要执行以下命令获取指定工作负载下每个压缩算法的压缩率信息:
$ tail -n +1 fio-bench-results/*/compratio
==> fio-bench-results/842/compratio <==
6.57
==> fio-bench-results/lz4/compratio <==
6.85
==> fio-bench-results/lz4hc/compratio <==
7.58
==> fio-bench-results/lzo/compratio <==
7.22
==> fio-bench-results/lzo-rle/compratio <==
7.14
==> fio-bench-results/zstd/compratio <==
9.48
依据以上衡量标准,笔者选出了该系统+该工作负载上最佳的配置(名称为压缩算法-page_cluster):
吞吐量最大:lz4hc-3 (19495 MiB/s)
延迟最低:lz4hc-0 (3189 ns)
IOPS 最高:lz4-0 (1982514 IOPS)
压缩率最高:zstd (9.48)
综合最佳:lz4hc-0
根据工作负载和需求的不同,读者可以选择适合自己的参数,也可以结合上面提到的多级 Swap,将 ZRAM 进一步分层,使用最高效的内存作为高优先级 Swap,压缩率最高的内存作为中低优先级 Swap。
如果测试机和生产环境的架构/硬件存在差异,可以将测试过程中导出的内存拷贝到生产环境,前提是两者运行相同的工作负载,否则测试内存无参考价值。
2. 配置 ZRAM 调优参数
上一张我们选出了综合最佳的 ZRAM 算法和参数,接下来就将其应用到我们的生产环境中。
2.1. 配置压缩算法,获得最佳压缩率
首先将压缩算法从默认的lzo-rle切换为lz4hc,根据 ZRAM 的文档,只需要将压缩算法写入/sys/block/zram0/comp_algorithm即可,考虑到我们配置/sys/block/zram0/disksize时的操作,我们重新编辑/etc/udev/rules.d/99-zram.rules文件,将其内容修改为:
- KERNEL=="zram0",ATTR{disksize}="30G",TAG+="systemd"
+ KERNEL=="zram0",ATTR{comp_algorithm}="lz4hc",ATTR{disksize}="30G",TAG+="systemd"
需要注意的是,必须先指定压缩算法,再指定磁盘大小,无论是在配置文件中还是直接echo参数到/sys/block/zram0设备上,都需要按照文档的顺序进行操作。
重启机器,再次执行cat /sys/block/zram0/comp_algorithm,就会发现当前压缩算法变成了lz4hc:

2.2. 配置 page-cluster,避免内存带宽和 CPU 资源的浪费
配置comp_algorithm后,接下来我们来配置page-cluster。
上面卖了不少关子,简单来说,page-cluster的作用就是每次从交换设备读取数据时多读 2^n 页,一些块设备或文件系统有簇的概念,读取数据也是按簇读取,假设内存页大小为 4KiB,而每次读取的一簇数据为 32KiB,那么把多读出来的数据也换回内存,就能避免浪费,减少频繁读取磁盘的次数,这一点在 Linux 的文档中也有提到:linux/vm.rst · torvalds/linux。默认的page-cluster大小为 3,即每次会从磁盘读取4K*2^3=32K的数据。
了解了page-cluster的原理后,我们会发现 ZRAM 并不属于传统的块设备,内存控制器默认设计就是按页读取,因此这一适用于磁盘设备的优化,在 ZRAM 场景下却是负优化,反而会导致过早触及内存带宽瓶颈和 CPU 解压缩瓶颈而导致性能下降,这也就可以解释为什么上面的表格中随着page-cluster的提升,吞吐量同样提升,而 IOPS 却变得更小,如果内存带宽和 CPU 解压缩不存在瓶颈,那么 IOPS 理论上应该保持不变。
考虑到无论是理论上,还是实际测试,page-cluster都是一个多余的优化,我们可以直接将其设置为 0。直接编辑/etc/sysctl.conf,在结尾新增一行:
vm.page-cluster=0
运行sysctl -p,即可让该设置生效,无需重启。
2.3. 让系统更激进地使用 Swap
上面性能测试中,lz4hc压缩参数下最小的平均读取延迟是 3203ns,即 0.003ms。与之对比,在笔者的电脑上,直接读取内存的延迟在 100ns 左右(0.0001ms,部分硬件可以到 50ns),SSD 读取一次的延迟一般是 0.05ms,而机械硬盘读取一次的延迟在 1ms~1000ms 之间。
不同层级存储设备读写的绝对时间与相对时间对比,可以看出它们之间指数级的差别。图片来自 cpu 内存访问速度,磁盘和网络速度,所有人都应该知道的数字 | las1991,最先出自于 Jeff Dean 的 PPT:Dean keynote-ladis2009。
也可以参考 rule-of-thumb-latency-numbers-letter.pdf 获取更详细的信息。
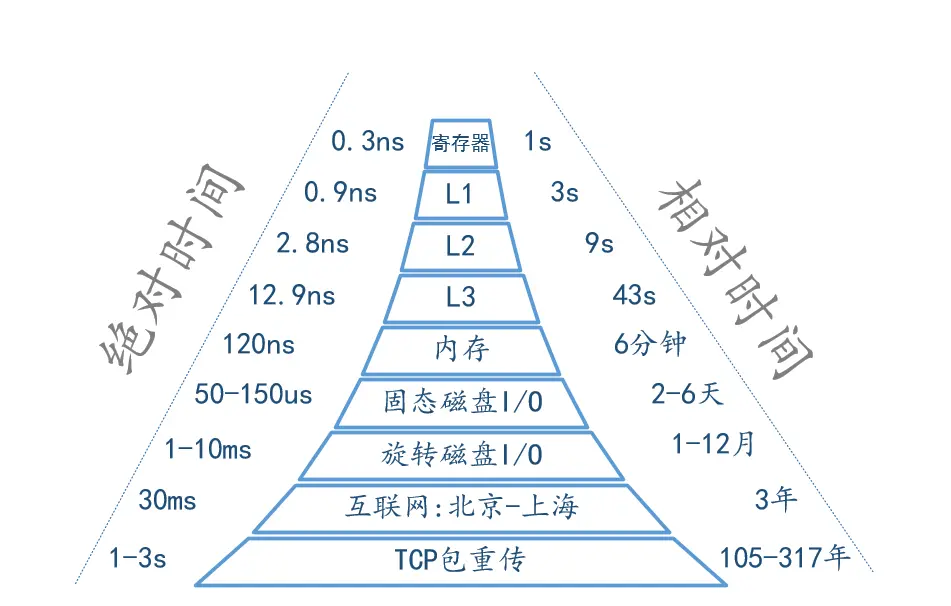
0.003ms 对比 1ms,是 300 多倍的差别,而 0.0001ms 对比 0.003ms 只有 30 多倍,这也就意味着 ZRAM 相比较 Swap 而言,更像是 RAM,既然如此,我们自然可以让 Linux 更激进地使用 Swap,而且让 ZRAM 尽可能早地获得更多可用内存空间。
这里我们需要了解两个知识:swappiness和内存碎片。
Swappiness 是一个内核参数,用于决定『内核有多倾向于在内存不足时换出到 Swap』,值越大倾向越大,关于 Swappiness,下一章会继续解释其作用,现在我们可以先认为这个值在 ZRAM 配置下越大越好,就算是 100(%) 也无所谓。
内存碎片则是一种现象,出现在长期运行的操作系统中,表现为内存有空余,但却因为没有足够大的连续空余导致无法申请到内存。无论该系统有无 MMU,都会不同程度在物理内存/虚拟内存/DMA 中遇到没有更多的连续空间分配给所需程序这一问题(曾经可用的连续空间都因为内存被无规律的释放后变得不连续,那些遗留且散落在内存空间中的数据就是所谓的内存碎片)。一般来说 Linux 会在出现内存碎片且认为有必要进行碎片整理时对内存进行整理。
为避免内存碎片,Linux 内存的分配和整理都遵循 Buddy System,即对内存页进行 2^n 次方分级,从 1 到 1024 总共 11 级,每一级都可以视为一组页框。例如一个进程需要 64 页的内存,操作系统会先从 64 页框的链表中寻找有无空闲,如果没有,再去 128 页框的链表中寻找,如果有,则将 128 页框的低端 64 页(左侧)分配出去,再将高端 64 页指向一个新的 64 页框链表。当释放内存时,由于申请的内存都是向页框低端对齐,当内存释放后,刚好也可以释放出一整个页框。
Buddy System 的设计极为巧妙,实现极为优雅,感兴趣的读者可以阅读 Buddy system 伙伴分配器实现 – youxin – 博客园 进一步了解其设计,此处不做过多赘述。Linux 中还有大量这样巧妙的设计,多了解有助于提升编程品味,笔者也处于学习过程中,希望能和读者共同进步。
上面提到内存碎片一般是在内存得到充分且长期利用后会出现的问题,而 ZRAM 则会导致可用内存不足时出现换页,这两个降低性能的操作基本上是同时发生的,也导致系统压力升高之后容易瞬间出现无响应现象,且可能因为来不及对内存进行碎片处理,导致 ZRAM 无法获取内存,进一步造成系统不稳定。
因此我们需要做的另一个操作就是尽可能让内存有序,尽可能在所需级别页框不足时立即触发碎片整理,充分压榨内存。Linux 中配置内存碎片整理条件的参数是vm.extfrag_threshold,当页框碎片指数低于该阈值则会触发碎片整理。碎片指数的计算方法可以参考 关于 linux 内存碎片指数 – _备忘录 – 博客园。总的来说,
综上所述,我们继续在/etc/sysctl.conf文件后添加以下两行:
# 默认是 500(介于 0 和 1000 之间的值)
vm.extfrag_threshold=0
# 默认是 60
vm.swappiness=100
这两个参数是笔者根据服务器内存使用情况、ZRAM 使用情况和碎片整理时机的监控信息来决定的,不一定适合所有场景,不设置这些参数也没有任何影响,如果不确定或不想做实验,不设置也没关系,仅供了解即可。
需要注意的是,关于swappiness参数,互联网上存在大量谬论,如swappiness最大值为 100,大多都将这个值当做一个百分数看待,接下来笔者将会解释为什么这个论点是错误的。
3. 为什么 ZRAM 没有被使用到
引言中提到的例子已经是一年之前的事情,当时在更小的圈子内做过一次分享。记得分享结束第二天,有朋友找上我,问为什么他配置了 ZRAM,且配置swappiness为 100,ZRAM 却一点没有被使用到。
现在想想看,其实这是一个非常普遍的问题,因此尽管这一节的标题为『为什么 ZRAM 没有被使用到』,接下来笔者想要分享的确是『到底在什么时候才会出现页面交换』这一问题。
互联网上对于如何配置软件,往往存在大量的 Myth,尤其是与性能优化相关的场景。开源软件尚且如此,闭源软件如 Windows 就更不用说,过时和虚假信息,夹杂着安慰剂效应成为了现今性能优化指南的一大特色,这些 Myth 不一定是作者主观故意,但背后也反映出了作者和读者都存在的惰性思维。
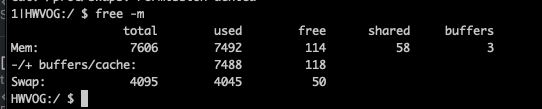
在了解swappiness之前,我们先了解 Linux 的内存回收机制。Linux 和其他现代操作系统一样,会倾向于提前使用内存,当我们运行free -m命令时,能看到以下参数,它们分别代表的是:

- total: 总内存量
- used: 进程所使用的内存量(部分系统下也包含 shared+buffer/cache,此时就是被操作系统使用的内存量)
- free: 没有被操作系统使用的内存量
- shared: 进程间共享内存量
- buff/cache: 缓冲区和缓存区
- available: 进程可以剩余使用的最大内存量
当我们说 Android 总是有多少内存吃多少时,我们通常指的是内存中 free 数量较少,这是相对于 Windows 而言,因为 Windows 将 free 定义为了 Linux 下 available 的含义,这并不代表 Windows 没有 buff/cache 的设计:
微软式中文经典操作:混淆 Free 和 Available,有机会笔者会分享一下 Windows 下各项内存参数的真实含义(比 Linux 混乱许多,而且很难自圆其说)。
简单来说,buffer是写入缓存,而cache是读取缓存,这两者统称文件页,Linux 会定期刷新写入缓存,但通常不会定期刷新读取缓存,这些缓存会占据内存的可用空间,当进程有新的内存需求时,Linux 依旧会从free中分配给进程,直到free的内存无法满足进程需求,此时 Linux 会选择回收文件页,供进程使用。
但如果将所有的文件页都给进程使用,就相当于 Linux 的文件缓存机制直接失效,尽管满足了内存使用,对 IO 性能却造成了影响,因此除了回收文件页以外,Linux 还会选择将页换出,即采用 Swap 机制,将暂时没有使用的内存数据(通常是匿名页,即堆内存)保存在磁盘中,称作换出。
一般来说,Linux 只有在内存紧张时才会选择回收内存,那么该如何衡量紧张呢?到达紧张状态后,又以什么标准退出紧张状态呢?这就要提到 Linux 的一个设计:内存水位线(Watermark)。
负责回收内存的内核线程kswapd0定义了一套衡量内存压力的标准,即内存水位线,我们可以通过/proc/zoneinfo文件获取水位线参数:
这个文件和上文提到的
/proc/buddyinfo有一个共性,即它们都将内存进行了分区,如 DMA、DMA32、Normal 等,具体可以阅读 Linux 内存管理机制简析 – 舰队 – 博客园,此处不再赘述,x86_64 架构下,这里我们只看 Normal 区域的内存即可。
$ cat /proc/zoneinfo
...
Node 0, zone Normal
pages free 12273184 # 空闲内存页数,此处大概空闲 46GB
min 16053 # 最小水位线,大概为 62MB
low 1482421 # 低水位线,大概为 5.6GB
high 2948789 # 高水位线,大概为 11.2GB
...
nr_free_pages 12273184 # 同 free pages
nr_zone_inactive_anon 1005909 # 不活跃的匿名页
nr_zone_active_anon 60938 # 活跃的匿名页
nr_zone_inactive_file 878902 # 不活跃的文件页
nr_zone_active_file 206589 # 活跃的文件页
nr_zone_unevictable 0 # 不可回收页
...
需要注意的是,由于 NUMA 架构下,每个 Node 都有自己的内存空间,因此如果存在多个 CPU,每个内存区域的水位线和统计信息是独立的。
首先我们来解释水位线,这里存在四种情况:
1. 当pages free小于pages min,说明所有内存耗尽,此时说明内存压力过大,会开始触发同步回收,表现为系统卡死,分配内存被阻塞,开始尝试碎片整理、内存压缩,如果都不奏效,则开始执行 OOM Killer,直到pages free大于pages high。
2. 当pages free在pages min和pages low之间,说明内存压力较大,kswapd0线程开始回收内存,直到pages free大于pages high。
3. 当pages free在pages low和pages high之间,说明内存压力一般,一般不会执行操作。
4. 当pages free大于pages high,说明内存基本上没有压力,无需回收内存。
接下来我们介绍swappiness这个参数的作用。从上面的过程可以得知,swappiness参数决定了kswapd0线程回收内存的策略。由于存在两类可被回收的内存页:匿名页和文件页,swappiness决定的则是匿名页相比较文件页被换出的比率,因为文件页的换出是直接将其回写到磁盘或销毁,这一参数也可以被解释为『Linux 在内存不足时回收匿名页的激进程度』。
同世间的其他事物一样,不存在绝对的好或坏,也很难给这些事物采用百分制打分,但我们可以通过利害关系来评估做一件事情的性价比,以最小的代价和最高的收益来实现目标,Linux 同样如此。根据mm/vmscan部分的 源码,我们可以发现 Linux 将swappiness带入如下算法:
anon_cost = total_cost + sc->anon_cost;
file_cost = total_cost + sc->file_cost;
total_cost = anon_cost + file_cost;
ap = swappiness * (total_cost + 1);
ap /= anon_cost + 1;
fp = (200 - swappiness) * (total_cost + 1);
fp /= file_cost + 1;
其中anon_cost和file_cost分别指对匿名页和文件页进行 LRU 扫描的难度。
假设进程需要内存,扫描两种内存页难度相同,且剩余内存小于低水位线,即当swappiness默认为 60 时,Linux 会选择回收文件页更多,当swappiness等于 100 时,Linux 会平等回收文件页和匿名页,而当swappiness大于 100,Linux 会选择回收匿名页更多。
根据 Linux 的 文档,如果使用 ZRAM 等比传统磁盘更快的 IO 设备,可以将swappiness设置到超过 100 的值,其计算方法如下:
For example, if the random IO against the swap device is on average 2x faster than IO from the filesystem, swappiness should be 133 (x + 2x = 200, 2x = 133.33).
经过这样的解释,相信读者应该既理解了swappiness的含义,也理解了为什么系统负载不高时,不管怎么设置swappiness,新申请的内存空间依旧不会被写入 ZRAM 中。
只有当内存不足,且swappiness较高时,配置 ZRAM 才会有比较可观的收益,但swappiness也不宜过高,否则文件页将会驻留在内存中,造成匿名页大量堆积在较慢的 ZRAM 设备中,反而降低性能。而且由于swappiness无法区分不同级别的 Swap 设备,如果使用了 ZRAM 和 Swapfile 分层,也需要将这一参数设置得更保守一些,通常来说 100 就是最合适的值。
4. 没有银弹
经过上文的详细解释,希望读者已经对 ZRAM 和 Linux 的内存模型有了较为详细和系统的理解。那么 ZRAM 是万能的吗?答案同样是否定的。
如果 ZRAM 是万能的,那么所有的发行版都应该默认启用 ZRAM,但情况并非如此。先不提 ZRAM 的配置取决于系统硬件与架构,不存在一招鲜吃遍天的参数,关键问题在 ZRAM 的性能。我们回到前面做性能测试输出的那张表格中,拿最好的 ZRAM 参数和直接访问内存盘的数据做对比,我们会得到以下结果:
algo | page-cluster| "MiB/s" | "IOPS" | "Mean Latency (ns)"| "99% Latency (ns)"
-------|-------------|-------------------|---------------|--------------------|-------------------
lz4hc | 0 | 7583.852120536133 | 1941466.478992| 3189.297915 | 9408
raw | 0 | 22850.29382917787 | 6528361.294582| 94.28362 | 190
可以看到,在性能方面,就算是最佳 ZRAM 配置,相比直接访问内存,依旧存在三倍以上的性能差距,更别提 30 倍的访存延迟(Apple Silcon 芯片之所以能够靠较低的功耗在各项性能上持平甚至领先 Intel,访存以及内存/显存复制的低延迟+夸张的内存带宽功不可没)。
成功的性能优化,绝不是一劳永逸的配置,如果真的那么简单,为什么软件不出厂就优化好呢?笔者认为,性能优化需要对架构和原理的充分了解,对需求和目标的提前预估,以及不断尝试、试验和对比。
这三者缺一不少,也并非互相孤立,往往做出最优选择需要在其中进行不断的取舍,正如上文在对比各种压缩算法和参数时,笔者列出来的那几项『吞吐量最大』、『延迟最低』、『IOPS 最高』、『压缩率最高』。后来笔者分别尝试过这几项,在对 ElasticSearch 进行基准测试时,性能反而不如默认的压缩算法,那这些所谓的『最』,到底有什么意义呢?
本文系笔者利用疫情隔离的周末闲暇,陆陆续续花费了 20 多小时写作完成,过程中为了避免出现错漏,查找了大量的资料,也进行了不少的实验,只希望带给读者综合的感官享受,让知识分享能更有趣、更深入,能启发读者进行扩展思考,结合自己的认知,让这篇文章能发挥知识分享以外的价值就再好不过。其中部分内容由于笔者个人能力限制、时间限制、审校不当等原因,可能存在疏漏甚至谬误,如您有更好的见解,欢迎指正,笔者一定虚心听取,有则改之,无则加勉。
写得很详细,感谢。
感谢分享