[源码级解析]分析并解决JavaScript里RegExp类中test()方法结果不固定的情况及其源码解析
本文完整阅读约需 58 分钟,如时间较长请考虑收藏后慢慢阅读~
在开发一个前端表单过程中,我使用了正则表达式对用户填写的内容进行校验,却在使用过程中发现了奇怪的现象:RegExp类的test()方法对同一字符串,在不同时间竟有不同的结果。本文将为读者分享我解决这一问题的方法及其背后的原理。
目录
0x01 问题重现
首先贴出示例代码:
let re = /[a-z]+/g;
console.log(re.test("abcde"));
console.log(re.test("abcde"));
console.log(re.test("abcde"));
console.log(re.test("abcde"));
console.log(re.test("abcde"));
console.log(re.test("abcde"));
console.log(re.test("abcde"));
console.log(re.test("abcde"));
console.log(re.test("abcde"));
执行后会发现,其返回结果不固定,且true与false相互交错。
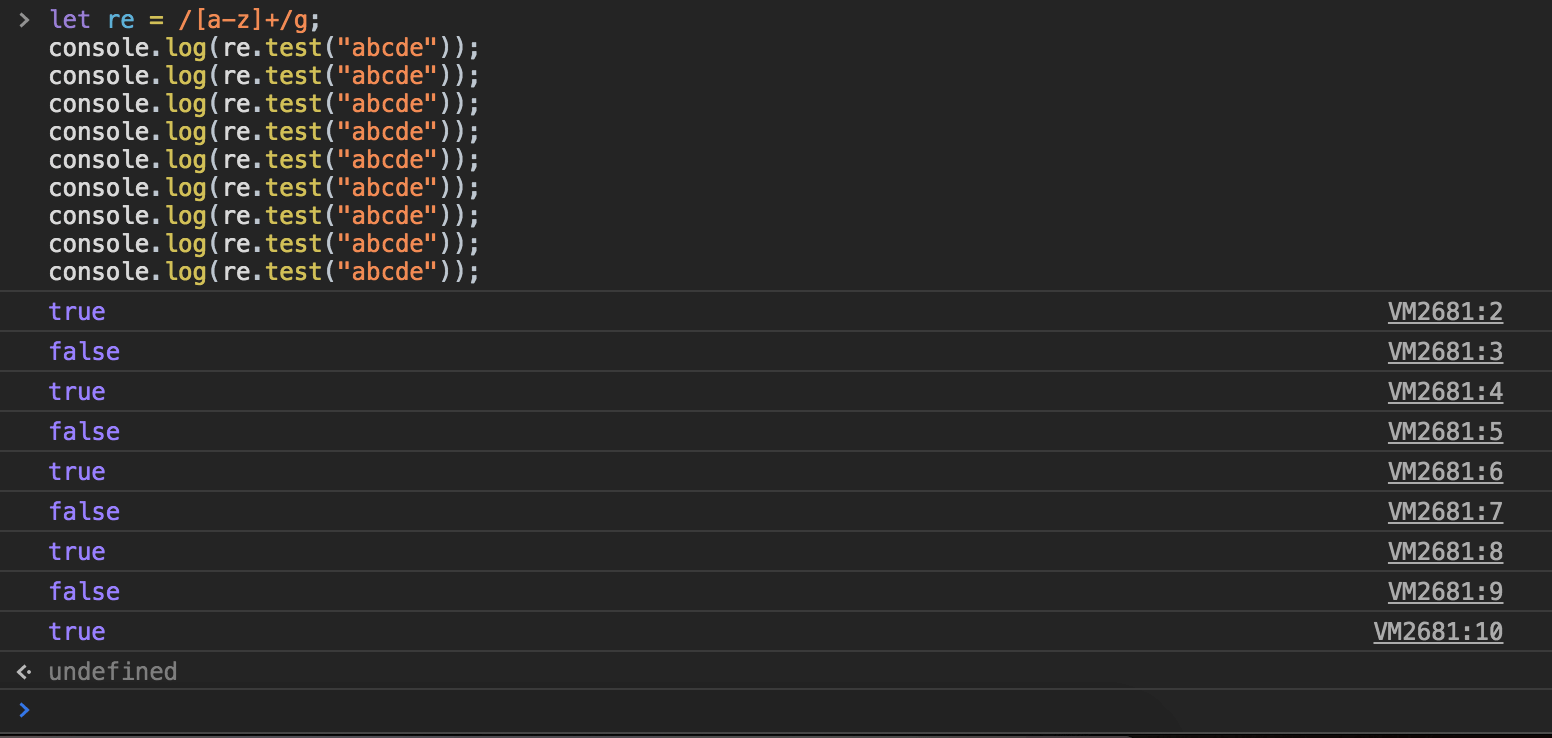
都说同样条件与状态下,计算机输出的结果应该一致,但这个时候,计算机却『说谎』了?
我当然不相信计算机会说谎。但在这背后一定有特定的原理。
0x02 思考&分析
考虑到JavaScript的/.../字面量是RegExp类的语法糖,我们就直接将眼光放到RegExp本身上。
我尝试在控制台输入RegExp,却意识到其实现并非自举(自举即Bootstrap,原意为提起鞋带让自己离开地面,在此处指用JS实现JS,类似的Bootstrap可参考Java/操作系统启动过程/PyPy等),仅返回了一个作为占位符的类别标识:ƒ RegExp() { [native code] }。
既然其提到了native code,那我们就从源码下手!
0x03 阅读源码
由于Chrome&Chromium的V8将Runtime与JIT重度耦合在了一起,我们以相对较为简单的Spidermonkey(Firefox的JS引擎)为例,后续再讲解V8中的情况。
大型开源项目的文件结构通常简明扼要,Spidermonkey也不例外:其关于正则表达式的源码存放于/js/src/builtin/RegExp.cpp中(参考地址),不超过1000行的源码让『阅读源码』这件事情从斩巨龙变成了吃蛋糕。
总结一下我们上面遇到的问题,会发现这一问题是在test()方法中出现的,那我们就从中搜索test,惊喜的发现:只有20个结果!这就又从吃蛋糕变成了浅酌一口清酒。
查看逐个搜索结果,我们发现了源码中的一条方法调用链:
JS_FN("test", regexp_test, 1,0)
↓
bool js::regexp_test(JSContext *cx, unsigned argc, Value *vp);
↓
static bool regexp_test_impl(JSContext *cx, CallArgs args);
↓
static RegExpRunStatus ExecuteRegExp(JSContext *cx, CallArgs args, MatchPairs &matches);
↓
RegExpRunStatus js::ExecuteRegExp(JSContext *cx, HandleObject regexp, HandleString string,
MatchPairs &matches, RegExpStaticsUpdate staticsUpdate);
最终调用的ExecuteRegExp()即为执行正则表达式匹配的方法。贴一部分源码在下面,方便大家阅读:
RegExpRunStatus
js::ExecuteRegExp(JSContext *cx, HandleObject regexp, HandleString string,
MatchPairs &matches, RegExpStaticsUpdate staticsUpdate)
{
/* Step 1 (b) was performed by CallNonGenericMethod. */
Rooted<RegExpObject*> reobj(cx, ®exp->as<RegExpObject>());
RegExpGuard re(cx);
if (!reobj->getShared(cx, &re))
return RegExpRunStatus_Error;
RegExpStatics *res;
if (staticsUpdate == UpdateRegExpStatics) {
res = cx->global()->getRegExpStatics(cx);
if (!res)
return RegExpRunStatus_Error;
} else {
res = nullptr;
}
/* Step 3. */
RootedLinearString input(cx, string->ensureLinear(cx));
if (!input)
return RegExpRunStatus_Error;
/* Step 4. */
RootedValue lastIndex(cx, reobj->getLastIndex());
size_t length = input->length();
/* Step 5. */
int i;
if (lastIndex.isInt32()) {
/* Aggressively avoid doubles. */
i = lastIndex.toInt32();
} else {
double d;
if (!ToInteger(cx, lastIndex, &d))
return RegExpRunStatus_Error;
/* Inlined steps 6, 7, 9a with doubles to detect failure case. */
if (reobj->needUpdateLastIndex() && (d < 0 || d > length)) {
reobj->zeroLastIndex();
return RegExpRunStatus_Success_NotFound;
}
i = int(d);
}
/* Steps 6-7 (with sticky extension). */
if (!re->global() && !re->sticky())
i = 0;
/* Step 9a. */
if (i < 0 || size_t(i) > length) {
reobj->zeroLastIndex();
return RegExpRunStatus_Success_NotFound;
}
/* Steps 8-21. */
size_t lastIndexInt(i);
RegExpRunStatus status = ExecuteRegExpImpl(cx, res, *re, input, &lastIndexInt, matches);
if (status == RegExpRunStatus_Error)
return RegExpRunStatus_Error;
/* Steps 9a and 11 (with sticky extension). */
if (status == RegExpRunStatus_Success_NotFound)
reobj->zeroLastIndex();
else if (reobj->needUpdateLastIndex())
reobj->setLastIndex(lastIndexInt);
return status;
}
在该方法中,我们看到了一个频繁出现的关键字lastIndex,在Step 6-7部分看到了对non-global && non-sticky状态下lastIndex的重置,在Step9a and 11部分同样可以看到在匹配结束后对lastIndex状态的修改。
可这个lastIndex是否就是我们所需要寻找的问题所在呢?这个时候,最简单的方法就是把它打印出来!
我们在return前面加一行代码,让其输出自己的lastIndex状态:
#include <iostream>
/* ... */
/* Steps 9a and 11 (with sticky extension). */
if (status == RegExpRunStatus_Success_NotFound)
reobj->zeroLastIndex();
else if (reobj->needUpdateLastIndex())
reobj->setLastIndex(lastIndexInt);
std::cout << reobj->getLastIndex().toInt32() << "\n";
return status;
接下来,我们直接编译之,然后运行dist/bin/js,在交互Shell下完成我们的测试。
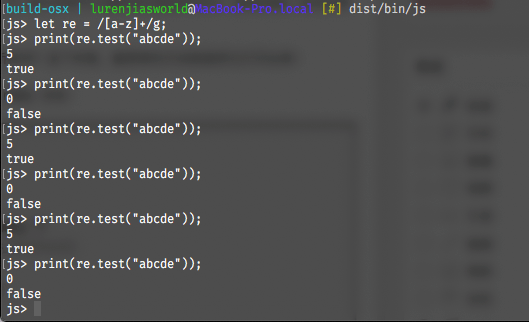
测试结果与上文所述基本一致,即true与false相互交错,但由于我们的修改,可以看到除了返回的status以外,还输出了当前的lastIndex。
看到lastIndex的变化,我们的疑惑瞬间就解除了!
0x04 分析源码
从上面的源码和输出结果可以显然看出来,lastIndex是正则表达式匹配之后的游标位置,下一次匹配会从游标开始,如果匹配不到,则重置游标到0的位置。在这里我用一个伪代码的图示表明其规则,更便于读者理解:
let re = /[a-z]+/g;
let str = "abcde"
// match 1
lastIndex = 0
abcde
_____^_____
lastIndex = 5
return true
// match 2
lastIndex = 5
abcde
______^____
lastIndex = ? // 无法匹配到下一个满足正则表达式的串
=> lastIndex = 0;
return false;
// match 3
lastIndex = 0;
abcde
_____^_____
lastIndex = 5
return true
......
如此理解,我们便了解了其机制。
0x05 深入理解
但读到这里,疑问却变得更大:为什么我之前使用test()方法不会发生这种情况呢?
我再将注意力放在上面代码的Step 6-7部分。
从这部分我们可以看到:在non-global && non-sticky状态下,lastIndex参数会在每次匹配前被置零,这也是我们所希望的结果,即每一次test()之间是独立的,不具有状态。
那么我们只要搞懂re->global()与re->sticky()是如何为真的,这个问题也就彻底揭开。
我们找到re对象的定义,即js/src/vm/RegExpObject.h,此处存储JS各对象的状态定义。
在其中,我们找到了global()和sticky()的定义:
bool global() const { return getFixedSlot(GLOBAL_FLAG_SLOT).toBoolean(); }
bool sticky() const { return getFixedSlot(STICKY_FLAG_SLOT).toBoolean(); }
可以看到,其体现出的是GLOBAL_FLAG与STICKY_FLAG的状态,再查找这两个常量,发现其还有一系列类似常量:
static const unsigned LAST_INDEX_SLOT = 0;
static const unsigned SOURCE_SLOT = 1;
static const unsigned GLOBAL_FLAG_SLOT = 2;
static const unsigned IGNORE_CASE_FLAG_SLOT = 3;
static const unsigned MULTILINE_FLAG_SLOT = 4;
static const unsigned STICKY_FLAG_SLOT = 5;
这些常量仅作为槽位标识,实际数据存储于fixedSlots中,通过getFixedSlot(SLOT_ID)进行定位。
理解了这一点之后,我们再去MDN上(网页链接)查找RegExp类的prototype,可以找到其中每一个常量对应的JSAPI:
RegExp.prototype.lastIndex
RegExp.prototype.source
RegExp.prototype.global
RegExp.prototype.ignoreCase
RegExp.prototype.multiline
RegExp.prototype.sticky
这就是RegExp类的状态及其在源码中的对应位置。
我们再次使用上文的cout大法,对其中的每个状态进行输出:
修改前:
// js/src/vm/RegExpObject.h
// ...
bool ignoreCase() const { return getFixedSlot(IGNORE_CASE_FLAG_SLOT).toBoolean(); }
bool global() const { return getFixedSlot(GLOBAL_FLAG_SLOT).toBoolean(); }
bool multiline() const { return getFixedSlot(MULTILINE_FLAG_SLOT).toBoolean(); }
bool sticky() const { return getFixedSlot(STICKY_FLAG_SLOT).toBoolean(); }
// ...
修改后:
bool ignoreCase() const { return getFixedSlot(IGNORE_CASE_FLAG_SLOT).toBoolean(); }
bool global() const {
std::cout << std::left << std::setw(24) << "LAST_INDEX_SLOT" << std::left << std::setw(10) << getFixedSlot(0).toBoolean() << "\n";
std::cout << std::left << std::setw(24) << "SOURCE_SLOT" << std::left << std::setw(10) << getFixedSlot(1).toBoolean() << "\n";
std::cout << std::left << std::setw(24) << "GLOBAL_FLAG_SLOT" << std::left << std::setw(10) << getFixedSlot(2).toBoolean() << "\n";
std::cout << std::left << std::setw(24) << "IGNORE_CASE_FLAG_SLOT" << std::left << std::setw(10) << getFixedSlot(3).toBoolean() << "\n";
std::cout << std::left << std::setw(24) << "MULTILINE_FLAG_SLOT" << std::left << std::setw(10) << getFixedSlot(4).toBoolean() << "\n";
std::cout << std::left << std::setw(24) << "STICKY_FLAG_SLOT" << std::left << std::setw(10) << getFixedSlot(5).toBoolean() << "\n";
return getFixedSlot(GLOBAL_FLAG_SLOT).toBoolean();
}
bool multiline() const { return getFixedSlot(MULTILINE_FLAG_SLOT).toBoolean(); }
bool sticky() const { return getFixedSlot(STICKY_FLAG_SLOT).toBoolean(); }
修改后,我们编译,然后在交互式命令行中输入let re = /[a-z]+/g;,得到如下输出:
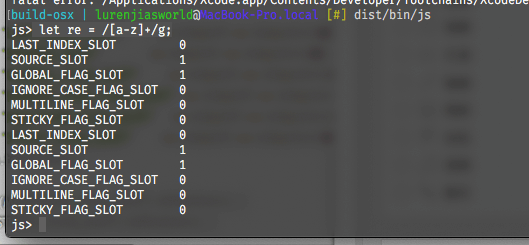
可以看到GLOBAL_FLAG_SLOT为1,即true。既然global状态存在,这就不难了解为什么lastIndex没有被置零。
我们继续进行实验,在交互式命令行中输入re.test("abc");,会得到如图所示的输出:
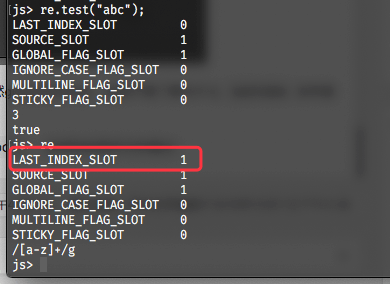
根据前文的分析,这里LAST_INDEX_SLOT应该为3,但此处显示1,是因为我们直接将所有结果都强制转换为了布尔类型。将这一参数输出修改为整型,再次编译即可得到正确输出:
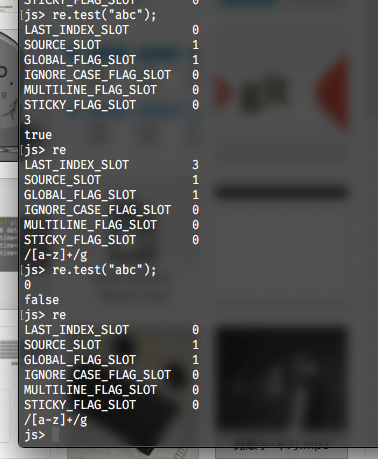
到这里,我们的疑惑已经基本解开,除了一点——到底在哪里配置的global属性呢?
前面的文章,我们分享了一个MDN的链接,点开链接,找到RegExp.prototype.global属性,可以找到如下描述:
global 属性表明正则表达式是否使用了 “g” 标志。global 是一个正则表达式实例的只读属性。
读到这里,拼图的最后一块也填满,本文所描述的问题也不再是问题。
整理一下:由于我们在声明正则表达式的时候配置了g字面量属性,使其在初始化的时候,将GLOBAL_FLAG_SLOT对应的fixedSlots置true。然后在执行test()方法时,其调用链的终点方法js::ExecuteRegExp会检查global参数或sticky参数(后面补充提及)是否为真,如果是则不对lastIndex复位,直接继承上一次的状态。而如果该方法匹配过程中发现接下来没有可以匹配的字串,则会继续复位lastIndex。这就是为什么同样的"abcde",输出结果会出现真假交替的情况。
0x06 扩展了解
上文我们提到了RegExp类的六个属性,但只讲了global与lastIndex两个,接下来我们来顺带了解剩下四个属性。
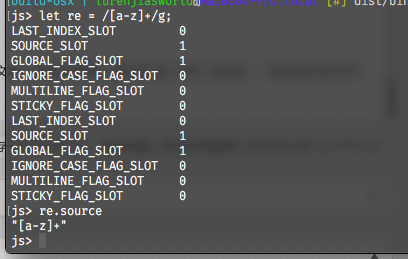
1. RegExp.prototype.source
这个属性指的是当前正则表达式对象的正则表达式文本,即本文举例/[a-z]+/g中的[a-z]+。在交互式命令行中的操作如下图所示:
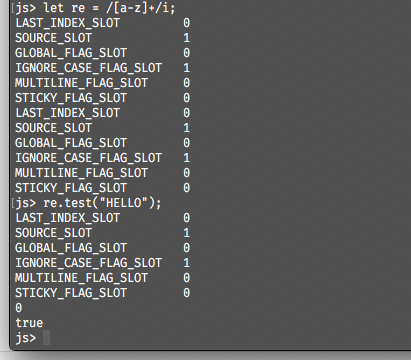
2. RegExp.prototype.ignoreCase
这个属性指的是当前正则表达式在匹配过程中是否忽略大小写,通过声明正则表达式时的字面量i触发,即let re = /[a-z]+/i;,如下图所示:
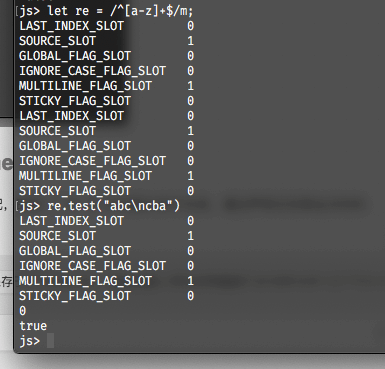
3. RegExp.prototype.multiline
这个属性指的是当前正则表达式是否允许多行匹配,即使^与$的匹配对多行生效,通过声明正则表达式时的字面量m触发,如下图所示:
若不配置该属性,结果为false,如下图所示:
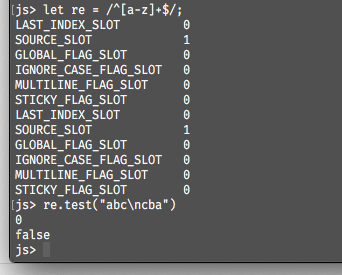
4. RegExp.prototype.sticky
从上面的源码分析可以看到,它与global在同一个地方被判断,而实际上它们的共性即为对lastIndex属性的依赖。sticky属性启用后,对应的匹配过程将仅从正则表达式的 lastIndex 属性表示的索引处为目标字符串开始。该属性通过正则表达式的字面量y触发。可能理解起来有一定难度,我们直接用代码说明:
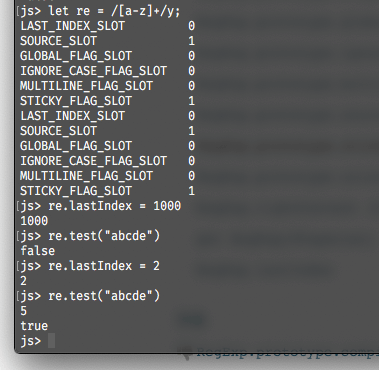
如果理解还是有困难,可以再结合其属性的单词:sticky(粘滞)理解,即不具有弹性,不会在每次匹配结束后自动归位,除非接下来没有任何可以匹配的字符串。
0x07 参考阅读:V8中关于本文的代码
上文提到,由于V8将Runtime与JIT紧密耦合在了一起,成为了一个项目,因此其阅读和分析过程较为复杂,因此简单起见,上文我只对SpiderMonkey做了分析。但在问题解决后,我觉得也应该为读者指明一下V8中对应的实现,以便大家在读完本文后,能进一步拓展知识面,学习到比我所介绍更多的内容,也不枉本文抛砖引玉之本意。
V8中相关的文件存放于src/runtime/runtime-regexp.cc,有RegExpBuiltinsAssembler::RegExpPrototypeSearchBodySlow和RegExpBuiltinsAssembler::RegExpPrototypeSearchBodyFast两个实现,用于不同的效率需求。
以RegExpBuiltinsAssembler::RegExpPrototypeSearchBodySlow举例,我们可以从源码中看到其清晰的匹配流程:
void RegExpBuiltinsAssembler::RegExpPrototypeSearchBodySlow(
Node* const context, Node* const regexp, Node* const string) {
CSA_ASSERT(this, IsJSReceiver(regexp));
CSA_ASSERT(this, IsString(string));
Isolate* const isolate = this->isolate();
Node* const smi_zero = SmiZero();
// Grab the initial value of last index.
Node* const previous_last_index =
SlowLoadLastIndex(CAST(context), CAST(regexp));
// Ensure last index is 0.
{
Label next(this), slow(this, Label::kDeferred);
BranchIfSameValue(previous_last_index, smi_zero, &next, &slow);
BIND(&slow);
SlowStoreLastIndex(context, regexp, smi_zero);
Goto(&next);
BIND(&next);
}
// Call exec.
Node* const exec_result = RegExpExec(context, regexp, string);
// Reset last index if necessary.
{
Label next(this), slow(this, Label::kDeferred);
Node* const current_last_index =
SlowLoadLastIndex(CAST(context), CAST(regexp));
BranchIfSameValue(current_last_index, previous_last_index, &next, &slow);
BIND(&slow);
SlowStoreLastIndex(context, regexp, previous_last_index);
Goto(&next);
BIND(&next);
}
// Return -1 if no match was found.
{
Label next(this);
GotoIfNot(IsNull(exec_result), &next);
Return(SmiConstant(-1));
BIND(&next);
}
// Return the index of the match.
{
Label fast_result(this), slow_result(this, Label::kDeferred);
BranchIfFastRegExpResult(context, exec_result, &fast_result, &slow_result);
BIND(&fast_result);
{
Node* const index =
LoadObjectField(exec_result, JSRegExpResult::kIndexOffset);
Return(index);
}
BIND(&slow_result);
{
Return(GetProperty(context, exec_result,
isolate->factory()->index_string()));
}
}
}
为便于阅读,给出一点提示:BIND()是注册锚点,Goto()是跳转到已注册的锚点,BranchIfSameValue(1, 2, 3, 4)是如果1=2则跳转到锚点3否则跳转到锚点4。结合注释与之前SpiderMonkey源码,即可大概分析出V8中类似的匹配逻辑。
可以从源码中看到,其对lastIndex的处理与SpiderMonkey有异曲同工之妙,只不过使用了SlowStoreLastIndex()和SlowLoadLastIndex()方法来辅助读写lastIndex属性。这是因为无论是什么JS引擎,都需要遵守EcmaScript的规范,该规范对所有JavaScript代码的行为、格式、标准库等都有所定义。如果是需要自己实现一个JavaScript引擎,一定要首先通读规范,然后将定义转换成代码,保证你的JavaScript引擎符合EcmaScript规范。
由于V8源码过于复杂,数量超过千万行,按照Nginx、Lua-JIT、SQLite的『通读源码』方案肯定是不现实的。如果对V8源码感兴趣,建议从如RegExp、Date等小的方面入手,一方面因为这些类的文档完整,另一方面,调试、阅读起来也更加容易,更有助于快速上手。实际上大部分时候对V8的魔改,也都是修改其与JS交互的部分,例如新增一个标准类、修改某个类的行为、新增一个类的方法等。
此外,若是希望更深入学习V8,可以看justjavac先生的知乎专栏:《V8、Chrome、Node.js》,希望也能对读者有循序渐进、持久且深入的帮助。
0x08 参考阅读:SpiderMonkey中曾经存在的一个趣味BUG
文章的最后,我来说一个SpiderMonkey中RegExp类所存在过一个很有意思的BUG。
当然这个BUG现在已经修复,但在我上文所贴的GitHub镜像代码库中还尚未修复,感兴趣的读者可以自行编译体验。该源码库尽管比较老,好在作者很友好的提供了主流操作系统编译脚本,存放于js/src/build-***目录,如果是学习使用,非常Handy,而实际上2015年至今的修改也不是那么多,学习用可以暂时忽略。
BUG描述如下:RegExp类在处理 ^ 断言和 sticky 标志时,会允许使用了 sticky 标志的表达式从 ^断言开始匹配。此外,这个 bug 是在 Firefox 3.6 之后的某个版本引入的(2010年发布的Firefox版本),并最终于2015年修复。
相关的Bugzilla地址:RegExp flag /y (sticky) causes ^ anchor to apply to start of match attempt rather than entire target string
可能上文描述过于抽象,尤其部分对『断言』了解不深的读者可能会更加一头雾水。没关系,我们换用更加形象的JS代码解释之:
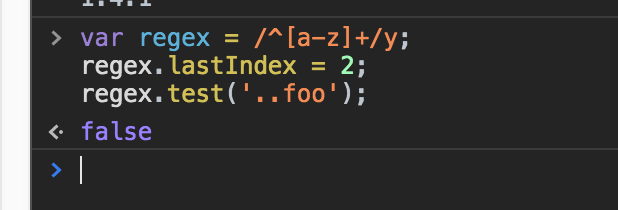
var regex = /^[a-z]+/y;
regex.lastIndex = 2;
regex.test("..foo");
在最新的Chrome77中,输出的结果与我们的预想一致:
但是在存在BUG的SpiderMonkey(或Firefox)中,输出结果则大不相同:
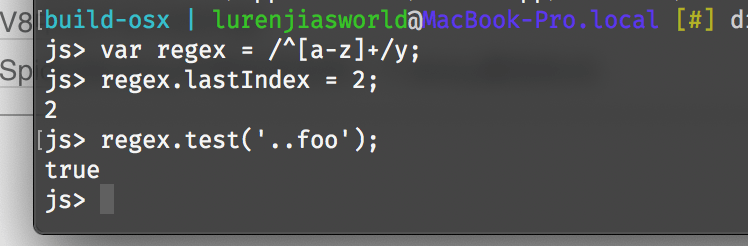
这个BUG在Rev-a567df6edc075cddf0d3c66d95c7a1e0cdd067ac后被修复,但由于这一BUG持久的存在,甚至影响到了ES2015的规范,规范特别指出:
NOTE: Even when the y flag is used with a pattern, ^ always matches only at the beginning of Input, or (if Multiline is true) at the beginning of a line.
注意:当使用带有y标识的匹配模式时,^断言总是会匹配输入的开始位置或者(如果是多行模式)每一行的开始位置。
可谓令人捧腹大笑,这是软件史上又一个成为Feature的BUG,对于开发者而言其趣味程度丝毫不亚于核爆甘地。而这也是开发的乐趣与魅力之一。人总会出错,但就算是最无法挽回的错误(参考Bumblebee直接搞挂操作系统的死亡空格),也会让人感到其背后的幽默(当然,对于资本家与所谓『软件工程师』除外)。
实际上,阅读源码同样也是如此。这本来是一个再小不过的问题,是我自己在学习JavaScript过程中不够仔细,忽略了global标签对test()方法行为的修改,但当我意识到错误并修改后,也丝毫不会妨碍我继续深入,探寻其原理。如果只是像CSDN上的大部分博主几句话解决问题,这篇文章又怎么会出现?难怪有人自称码农,嫌弃开发无趣!