Linux下快速生成大量文件的若干小技巧
本文完整阅读约需 10 分钟,如时间较长请考虑收藏后慢慢阅读~
最近参与了一款类Haystack存储引擎的开发,在开发的后期需要进行性能测试,即需要大量小文件作为测试素材。考虑到文件数量以千万/亿记,因此如何快速生成这些文件十分重要。这篇文章为大家分享一下我的探索过程,以及多种生成大量文件的方案。
0x01 笨办法
既然是生成文件,我们首先想到的是逐个写入。于是我撰写了以下脚本:
mkdir data
for ((i = 1; i <= $1; i++)); do
dd if=/dev/zero of=./data/${i}.bin bs=${2}k count=1 &>/dev/null
done
该脚本接收两个参数:
1. 生成的文件个数
2. 生成的文件大小(KB)
调用方法如下所示:
./gen_v1.sh 10000 16
即生成10000个16KB的文件在当前目录的data目录下。
0x02 另一个笨办法
如果希望大小随机,可以使用如下变种脚本:
mkdir data
for ((i = 1; i <= $1; i++)); do
dd if=/dev/zero of=./data/${i}.bin bs=`shuf -n 1 -i ${2}-${3}`k count=1 &>/dev/null
done
该脚本接收三个参数:
1. 生成的文件个数
2. 生成文件的最小体积(KB)
3. 生成文件的最大体积(KB)
调用方法如下所示:
./gen_v2.sh 10000 4 32
即生成10000个大小在4~32KB(随机)的文件在当前目录的data目录下。
0x03 巧办法
上面的笨办法尽管直接,但却不够高效。
使用strace对以上命令生成文件过程中的系统调用进行追踪,很容易发现在执行过程中,操作系统不断的对/dev/zero和目标文件进行open、close与dup2三个系统调用,极其影响性能。
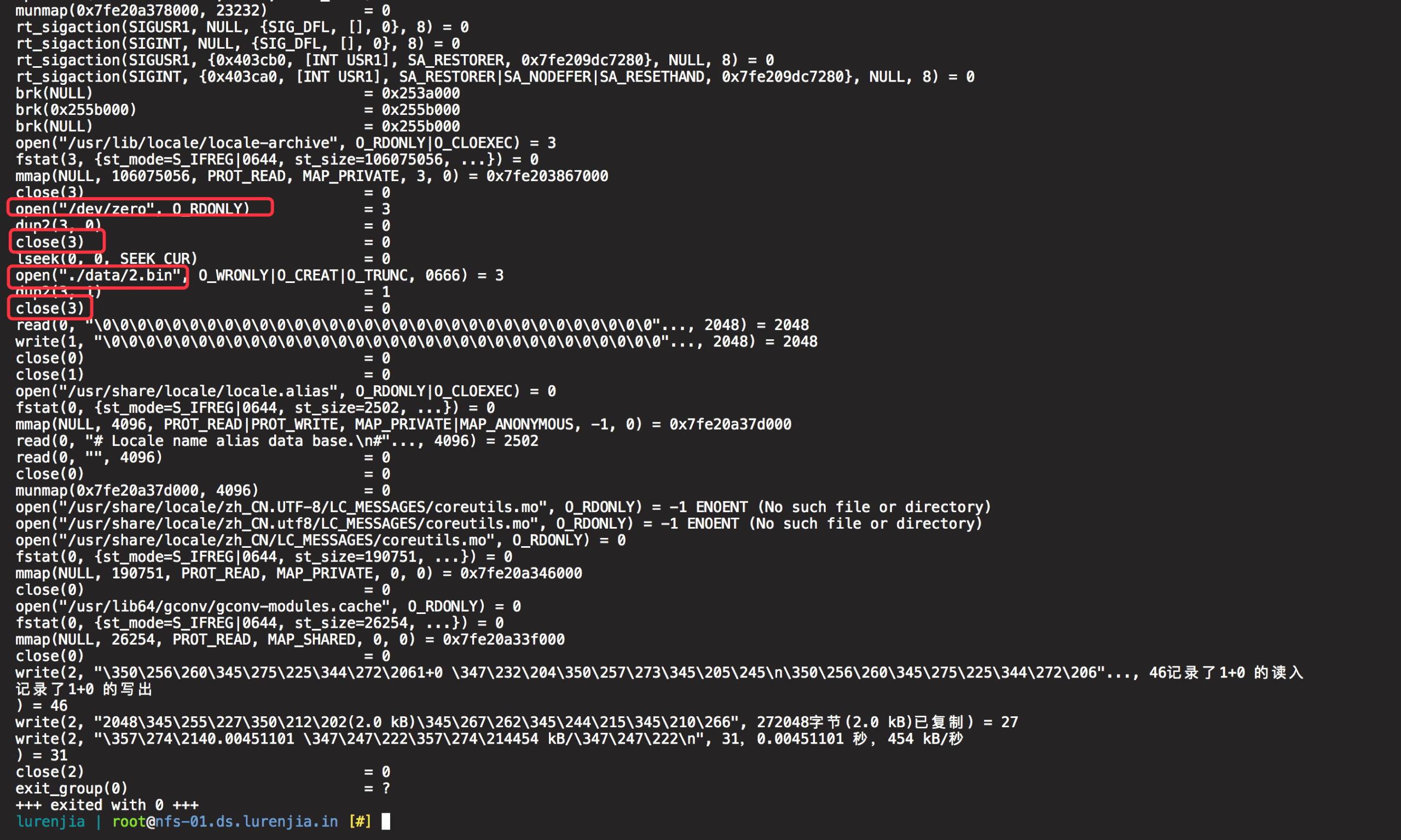
因此,我想到使用split来避免文件的来回复制,只需要复制一个文件块,然后分割这个文件块来变相实现大量文件的快速生成。
代码如下所示:
mkdir data
count=$1
size=$2
total_size=`expr $count \* $size`
dd bs=${total_size}k count=1 if=/dev/zero | split -b ${size}k -a ${#count} -d - "./data/"
该脚本接收两个参数:
1. 生成的文件个数
2. 生成的文件大小(KB)
调用方法如下所示:
./gen_v3.sh 1000 1024
即生成1000个1024KB(1MB)的文件。
0x04 不那么巧的巧办法
考虑到split生成的文件大小相同,因此使用该方法生成随机大小的文件有难度,建议使用
0x02节中的方法(尽管性能较差)
但如果实在希望能用split实现该功能,也是可行的,只是要损失精确的文件数量:
mkdir data
count=$1
min_size=$2
max_size=$3
file_block_size=4096
ratio=`echo "$file_block_size / (($min_size + $max_size) / 2)" | bc`
iter_count=`expr $count / $ratio`
for ((i = 1; i <= $iter_count; i++)); do
dd bs=${file_block_size}k count=1 if=/dev/zero | split -b `shuf -n 1 -i ${min_size}-${max_size}`k -a 3 -d - "./data/$i-"
done
该脚本接收三个参数:
1. 生成的文件个数(近似值)
2. 生成文件的最小体积(KB)
3. 生成文件的最大体积(KB)
调用方法如下所示:
./gen_v4.sh 10000 4 32
即生成大约10000个大小在4~32KB(随机)的文件在当前目录的data目录下。
需要注意的是,该脚本的文件数量与实际文件数量存在差距,但差距不大。以上面的示例调用为例,三次操作后实际生成的文件数量分别为:15283、15220、16075。
多次测试发现,实际文件数量均大于所需文件数量。因此如果对文件数量的精确度有要求,可以自行在脚本后添加以下内容删除多余文件:
file_true_count=`echo "\`ls -l data | wc -l\`-1" | bc`
count_diff=`echo "$file_true_count-$count+1" | bc`
cd data && rm -rf `ls -l ./ | tail -n ${count_diff} | awk '{print $9}' | tr "\n" " "
注意:以上生成的随机文件文本均为空,如果需要修改为随机数据,替换
/dev/zero为/dev/urandom即可。
以上就是四种在Linux下快速生成大量文件的方法,如果你有更好的方法,欢迎在评论中提出,供其他读者进一步参考。